KMP字符串模式匹配
本文共 6210 字,大约阅读时间需要 20 分钟。
KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。简单匹配算法的时间复杂度为O(m*n);KMP匹配算法。可以证明它的时间复杂度为O(m+n).。
一.简单匹配算法
/** * 1. 普通算法 * 从字符数组S中找到与字符数组T匹配的起始字符的下标索引值 * @param S * 预查找的源字符串数组 * @param T * 预查找的目标字符串数组 * @param pos * 从源字符数组的第pos位下标开始查找 * @return * 若找到T在S中的完全匹配,则返回T首字符在S中的下标位置值, * 否则返回-1. */ @SuppressWarnings("unused") private static int getStrStartIndex(char[] S,char[] T ,int pos){ //i 作为S数组的下标索引 int i = pos; //j作为T数组的索引 int j = 0; while((i+j) != S.length && j != T.length) { if(S[i+j] == T[j]){ //继续后续字符的比较 j ++; } else { //重新开始新的一轮比较,S的下标后移一位,T数组索引重0开始 i ++; j = 0; } } if(j== T.length){ //完全匹配,返回下标 return i; } else { //匹配失败,返回-1 return -1; } } 此算法的思想是直截了当的:将主串 S 中某个位置 i 起始的子串和模式串 T 相比较。即从 j=0 起比较 S[i+j] 与 T[j] ,若相等,则在主串 S 中存在以 i 为起始位置匹配成功的可能性,继续往后比较 ( j 逐步增 1 ) ,直至与 T 串中最后一个字符相等为止,否则改从 S 串的下一个字符起重新开始进行下一轮的 " 匹配 " ,即将串 T 向后滑动一位,即 i 增 1 ,而 j 退回至 0 ,重新开始新一轮的匹配。
例如:在串 S= ”abcabcabdabba” 中查找 T=” abcabd” (我们可以假设从下标 0 开始) : 先是比较 S[0] 和 T[0] 是否相等,然后比较 S[1] 和 T[1] 是否相等 … 我们发现一直比较到 S[5] 和 T[5] 才不等。如图:
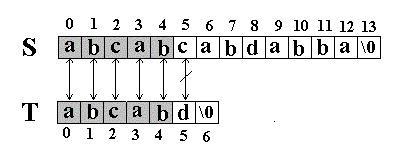
当这样一个失配发生时, T 下标必须回溯到开始, S 下标回溯的长度与 T 相同,然后 S 下标增 1, 然后再次比较。如图:
这次立刻发生了失配, T 下标又回溯到开始, S 下标增 1, 然后再次比较。如图:
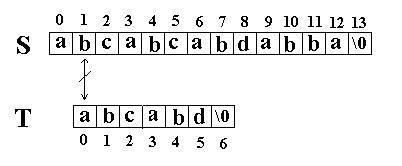
这次立刻发生了失配, T 下标又回溯到开始, S 下标增 1, 然后再次比较。如图:
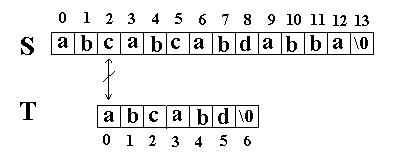
又一次发生了失配,所以 T 下标又回溯到开始, S 下标增 1, 然后再次比较。这次 T 中的所有字符都和 S 中相应的字符匹配了。函数返回 T 在 S 中的起始下标 3 。如图: 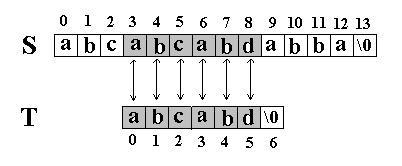
二. KMP匹配算法
还是相同的例子,在 S= ”abcabcabdabba” 中查找 T =”abcabd” ,如果使用 KMP 匹配算法,当第一次搜索到 S[5] 和 T[5] 不等后, S 下标不是回溯到 1 , T 下标也不是回溯到开始,而是根据 T 中 T[5]==’d’ 的模式函数值( next[5]=2 ,为什么?后面讲),直接比较 S[5] 和 T[2] 是否相等,因为相等, S 和 T 的下标同时增加 ; 因为又相等, S 和 T 的下标又同时增加。。。最终在 S 中找到了 T 。如图:
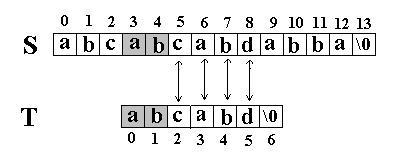
KMP 匹配算法和简单匹配算法效率比较,一个极端的例子是:
在 S= “ AAAAAA…AAB “ (100 个 A) 中查找 T=”AAAAAAAAAB”, 简单匹配算法每次都是比较到 T 的结尾,发现字符不同,然后 T 的下标回溯到开始, S 的下标也要回溯相同长度后增 1 ,继续比较。如果使用 KMP 匹配算法,就不必回溯 .
对于一般文稿中串的匹配,简单匹配算法的时间复杂度可降为 O (m+n) ,因此在多数的实际应用场合下被应用。
KMP 算法的核心思想是利用已经得到的部分匹配信息来进行后面的匹配过程。看前面的例子。为什么 T[5]==’d’ 的模式函数值等于 2 ( next[5]=2 ),其实这个 2 表示 T[5]==’d’ 的前面有 2 个字符和开始的两个字符相同,且 T[5]==’d’ 不等于开始的两个字符之后的第三个字符( T[2]=’c’ ) . 如图:
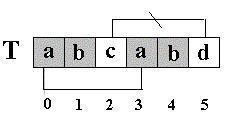
也就是说,如果开始的两个字符之后的第三个字符也为 ’d’, 那么,尽管 T[5]==’d’ 的前面有 2 个字符和开始的两个字符相同, T[5]==’d’ 的模式函数值也不为 2 ,而是为 0 。
前面我说:在 S= ”abcabcabdabba” 中查找 T =”abcabd” ,如果使用 KMP 匹配算法,当第一次搜索到 S[5] 和 T[5] 不等后, S 下标不是回溯到 1 , T 下标也不是回溯到开始,而是根据 T 中 T[5]==’d’ 的模式函数值,直接比较 S[5] 和 T[2] 是否相等。。。为什么可以这样?
刚才我又说:“( next[5]=2 ),其实这个 2 表示 T[5]==’d’ 的前面有 2 个字符和开始的两个字符相同”。请看图 :因为, S[4] ==T[4] , S[3] ==T[3] ,根据 next[5]=2 ,有 T[3]==T[0] , T[4] ==T[1] ,所以 S[3]==T[0] , S[4] ==T[1] (两对相当于间接比较过了),因此,接下来比较 S[5] 和 T[2] 是否相等。。。
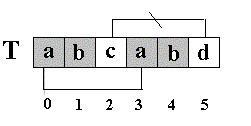
有人可能会问: S[3] 和 T[0] , S[4] 和 T[1] 是根据 next[5]=2 间接比较相等,那 S[1] 和 T[0] , S[2] 和 T[0] 之间又是怎么跳过,可以不比较呢?因为 S[0]=T[0] , S[1]=T[1] , S[2]=T[2] ,而 T[0] != T[1], T[1] != T[2],==> S[0] != S[1],S[1] != S[2], 所以 S[1] != T[0],S[2] != T[0]. 还是从理论上间接比较了。
有人疑问又来了,你分析的是不是特殊轻况啊。
假设 S 不变,在 S 中搜索 T= “ abaabd ”呢?答:这种情况,当比较到 S[2] 和 T[2] 时,发现不等,就去看 next[2] 的值, next[2]=-1 ,意思是 S[2] 已经和 T[0] 间接比较过了,不相等,接下来去比较 S[3] 和 T[0] 吧。
假设 S 不变,在 S 中搜索 T= “ abbabd ”呢?答:这种情况当比较到 S[2] 和 T[2] 时,发现不等,就去看 next[2] 的值, next[2]=0 ,意思是 S[2] 已经和 T[2] 比较过了,不相等,接下来去比较 S[2] 和 T[0] 吧。
假设 S=” abaabcabdabba ” 在 S 中搜索 T= “ abaabd ”呢?答:这种情况当比较到 S[5] 和 T[5] 时,发现不等,就去看 next[5] 的值, next[5]=2 ,意思是前面的比较过了,其中, S[5] 的前面有两个字符和 T 的开始两个相等,接下来去比较 S[5] 和 T[2] 吧。
总之,有了串的 next 值,一切搞定。那么,怎么求串的模式函数值 next[n] 呢?(本文中 next 值、模式函数值、模式值是一个意思。)
三. 怎么求串的模式值next[n]
定义 :
( 1 ) next[0]= -1 意义:任何串的第一个字符的模式值规定为 -1 。
( 2 ) next[j]= -1 意义:模式串 T 中下标为 j 的字符,如果与首字符
相同,且 j 的前面的 1—k 个字符与开头的 1—k
个字符不等(或者相等但 T[k]==T[j] )( 1 ≤ k<j )。
如: T=”abCabCad” 则 next[6]=-1 ,因 T[3]=T[6]
( 3 ) next[j]=k 意义:模式串 T 中下标为 j 的字符,如果 j 的前面 k 个
字符与开头的 k 个字符相等,且 T[j] != T[k] ( 1 ≤ k<j )。
即 T[0]T[1]T[2] 。。。 T[k-1]==
T[j-k]T[j-k+1]T[j-k+2]…T[j-1]
且 T[j] != T[k]. ( 1 ≤ k<j ) ;
(4) next[j]=0 意义:除( 1 )( 2 )( 3 )的其他情况
举例 :
01 ) 求 T= “ abcac ”的模式函数的值。
next[0]= -1 根据( 1 )
next[1]=0 根据 (4) 因( 3 )有 1<=k<j; 不能说, j=1,T[j-1]==T[0]
next[2]=0 根据 (4) 因( 3 )有 1<=k<j; ( T[0]=a ) != ( T[1]=b )
next[3]= -1 根据 (2)
next[4]=1 根据 (3) T[0]=T[3] 且 T[1]=T[4]
即
| 下标 | 0 | 1 | 2 | 3 | 4 |
| T | a | b | c | a | c |
| next | -1 | 0 | 0 | -1 | 1 |
若 T= “ abcab ”将是这样:
| 下标 | 0 | 1 | 2 | 3 | 4 |
| T | a | b | c | a | b |
| next | -1 | 0 | 0 | -1 | 0 |
为什么 T[0]==T[3], 还会有 next[4]=0 呢 , 因为 T[1]==T[4], 根据 (3)” 且 T[j] != T[k]” 被划入( 4 )。
02 )来个复杂点的,求 T=”ababcaabc” 的模式函数的值。
next[0]= -1 根据( 1 )
next[1]=0 根据 (4)
next[2]=-1 根据 (2)
next[3]=0 根据 (3) 虽 T[0]=T[2] 但 T[1]=T[3] 被划入( 4 )
next[4]=2 根据 (3) T[0]T[1]=T[2]T[3] 且 T[2] !=T[4]
next[5]=-1 根据 (2)
next[6]=1 根据 (3) T[0]=T[5] 且 T[1]!=T[6]
next[7]=0 根据 (3) 虽 T[0]=T[6] 但 T[1]=T[7] 被划入( 4 )
next[8]=2 根据 (3) T[0]T[1]=T[6]T[7] 且 T[2] !=T[8]
即
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| T | a | b | a | b | c | a | a | b | c |
| next | -1 | 0 | -1 | 0 | 2 | -1 | 1 | 0 | 2 |
只要理解了 next[3]=0 ,而不是 =1 , next[6]=1 ,而不是 = -1 , next[8]=2 ,而不是 = 0 ,其他的好象都容易理解。
03) 来个特殊的,求 T=”abCabCad” 的模式函数的值。
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| T | a | b | C | a | b | C | a | d |
| next | -1 | 0 | 0 | -1 | 0 | 0 | -1 | 4 |
next[5]= 0 根据 (3) 虽 T[0]T[1]=T[3]T[4], 但 T[2]==T[5]
next[6]= -1 根据 (2) 虽前面有 abC=abC, 但 T[3]==T[6]
next[7]=4 根据 (3) 前面有 abCa=abCa, 且 T[4]!=T[7]
若 T[4]==T[7] ,即 T=” adCadCad”, 那么将是这样: next[7]=0, 而不是 = 4, 因为 T[4]==T[7].
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| T | a | d | C | a | d | C | a | d |
| next | -1 | 0 | 0 | -1 | 0 | 0 | -1 | 0 |
/** * 获得字符串的next函数值 * * @param t * 字符串 * @return next函数值 */ public static int[] next(char[] t) { int[] next = new int[t.length]; next[0] = -1; int i = 0; int j = -1; while (i < t.length - 1) { if (j == -1 || t[i] == t[j]) { i++; j++; if (t[i] != t[j]) { next[i] = j; } else { next[i] = next[j]; } } else { j = next[j]; } } return next; } /*
* KMP匹配字符串 * * @param s * 主串 * @param t * 模式串 * @return 若匹配成功,返回下标,否则返回-1 */ public static int KMP_Index(char[] s, char[] t , int startPos) { int[] next = next(t); int i = startPos; int j = 0; while (i <= s.length - 1 && j <= t.length - 1) { if (j == -1 || s[i] == t[j]) { i++; j++; } else { j = next[j]; } } if (j < t.length) { return -1; } else { return i - t.length; // 返回模式串在主串中的头下标 } }
你可能感兴趣的文章
mongodb管理与安全认证
查看>>
nodejs内存控制
查看>>
nodejs Stream使用中的陷阱
查看>>
MongoDB 数据文件备份与恢复
查看>>
数据库索引介绍及使用
查看>>
MongoDB数据库插入、更新和删除操作详解
查看>>
MongoDB文档(Document)全局唯一ID的设计思路
查看>>
mongoDB简介
查看>>
Redis持久化存储(AOF与RDB两种模式)
查看>>
memcached工作原理与优化建议
查看>>
Redis与Memcached的区别
查看>>
redis sharding方案
查看>>
程序员最核心的竞争力是什么?
查看>>
Node.js机制及原理理解初步
查看>>
linux CPU个数查看
查看>>
分布式应用开发相关的面试题收集
查看>>
简单理解Socket及TCP/IP、Http、Socket的区别
查看>>
利用HTTP Cache来优化网站
查看>>
利用负载均衡优化和加速HTTP应用
查看>>
消息队列设计精要
查看>>